
Step One and Done: The Prime Mover Mindset for the AI Age
Own the start and the finish. Let AI handle the messy middle.


Everyone has an opinion about AI.
Enthusiasts say it will create abundance.
Skeptics say it will destroy jobs.
Money is talking — nearly half a trillion dollars’ worth.
In 2025 alone, Amazon, Meta, Alphabet, Microsoft, and Oracle committed $399 billion to AI infrastructure. Projections push that past $600 billion.
Deutsche Bank estimates spending on AI data centers will reach $4 trillion through 2030.
That’s ten times the inflation-adjusted cost of the Apollo program.
And it’s already showing up outside tech budgets. U.S. GDP grew 4.3% in Q3, but the story gets narrow fast: private fixed investment is rising largely because of AI-related spending.
Adoption is already widespread. 72% of companies use AI in at least one business area. ChatGPT crossed 800 million weekly active users.
And the message has gone mainstream. Here’s Marc Benioff in The Wall Street Journal, selling “agentic enterprise” as the new default.

Pull AI-related spend out of the investment numbers, and Deutsche Bank says the U.S. economy would be close to recession.
The debate about whether AI will matter is happening inside an economy that’s already been built around the assumption that it will.
The strategic question is what your operating model looks like while all of it is happening.
Every major economic transition rewards clarity.
The leaders who do well can name what they’re building and what “done” looks like.
The ones who stall try to control the middle—choreographing every step, managing every variable, sitting through meetings that exist because nobody agreed on the destination.
A model like this existed long before business frameworks:

The farmer.
For most of human history, farming was the work. Then industry displaced it. Farmers adapted, scaled, mechanized, or left the field. But the mindset that kept them alive didn’t vanish. It’s built for uneven ground:
Pests.
Soil shifts.
Weather turns.
Market swings.
Farmers don’t survive by mastering every variable. They survive by reducing the chaos to one question:
Does this serve what I’m growing?
That filter turns noise into action. Forecasts become planting calls. Soil data becomes crop choices. Pest knowledge becomes protection. The farmer wins by setting conditions and judging everything by the harvest.
The Farmer’s Almanac captured the same logic.
It didn’t try to explain the world in full. It compressed patterns into choices you could make, organized around the harvest.
And the work followed a practical order. Learn what the weeds tell you. Then understand the pests. Then improve the soil. Then think across seasons. Each layer matters only if it helps what’s growing.
Handle the inputs. Define the harvest.
Everything in the middle is the system—conditions, constraints, timing.
When the inputs are right and 'done' is clear, hail doesn't send you back to the beginning. It sends you to the almanac. You check what the crop needs now, adjust, and keep moving. Every surprise still runs through the same filter:
Does this serve the harvest?
That’s the mindset worth bringing back.
A way of running work that holds up when the transition won’t sit still.
Specialization broke the loop.
We over-specialized the process and lost the harvest.
It happened slowly. As economies moved from agricultural to industrial, value moved from land to institutions. Work moved indoors. Scale demanded division. Division demanded specialization.
The farmer’s integrated loop got split into roles. Meteorology became a career. Geology became a department. Botany became an identity. What used to serve the harvest became the job—and the job drifted from the outcome.
The loop broke.
The textbook replaced the almanac. The almanac organized knowledge around one question: what does the harvest need? The textbook organized knowledge around a different one: what does this discipline contain? For a century, that model won because industrial scale needed it.
That shift changed what competence meant.
When value sits in land and harvest, you need people who can hold the whole loop. When value moves to institutions and scale, you need people who go deep in a bounded slice. The industrial age made “depth” the standard, measured by credentials and throughput.
Now look at how most organizations actually run. Not on shared models—on meetings. Context gets rebuilt, used once, and then expires. Next meeting, you rebuild it again. That’s the patchwork.
That’s also why language models land so hard. They beat specialists at processing the slices. They don’t replace the job of building the model that connects the slices—working backward from “done,” then forward to test what you thought was true.
If your value is “I process information in a bounded domain,” you’re in a race with something that improves faster than you do.
The farmer competed on judgment. Value lived in the decisions that linked inputs to harvest. Processing any single input was the cheapest part of the loop.
Nobody set out to become a process operator. Institutions trained it in. Incentives locked it in. Reviews measured it. Promotions rewarded it. And over time, specialization started to look like the point.
That bias is still baked into org charts, hiring, and how leaders spend their day.
The industrial age didn’t just produce specialists.
It produced people who forgot what they were specializing for.
Most leaders live in the middle.
Look at your calendar and count the decisions your team is waiting on.
Now count the ones that truly require your judgment—the kind that depends on context only you hold.
That number is smaller than your week suggests.
Most of what fills a leader’s schedule is the middle: the handoffs, the check-ins, the approvals, the updates. Not because the work is hard, but because “done” was never made clear enough for the system to run without you.
You can see it in your meetings:
Check-ins because the endpoint stayed fuzzy.
Sync meetings because shared direction drifted.
Reviews because the model lived in one person’s head.
Status updates because the work can’t report its own state.
Each one is a workaround. Each one is a step you’re maintaining.
And the standard advice is to make the workarounds quicker. Shorter meetings. Fewer touchpoints. Batch approvals. Push updates async. You get better at pushing traffic through the middle.
But you’re still pushing traffic.
A big chunk of what you call “process” is just payment for missing clarity.
People start work without a shared definition of success, so the middle expands to carry what the start didn’t provide.
Farmers don’t escape uncertainty. They live in it. The difference is that the target is shared and the signals are visible. When the leaves yellow, when the soil stays dry, when pests show up, the work changes. Decisions get checked against the harvest, not against whoever holds the most context.
Most teams run the opposite way. The system can’t move on its own, so everything routes through you. You’re not leading. You’re load-bearing.
That’s the dangerous middle: a week spent managing traffic in a system that never agreed on the destination. It looks like productivity. It’s just motion.
Clarity doesn’t cut steps. It changes which steps deserve to exist.
AI can rebuild the loop—if you start with “done.”
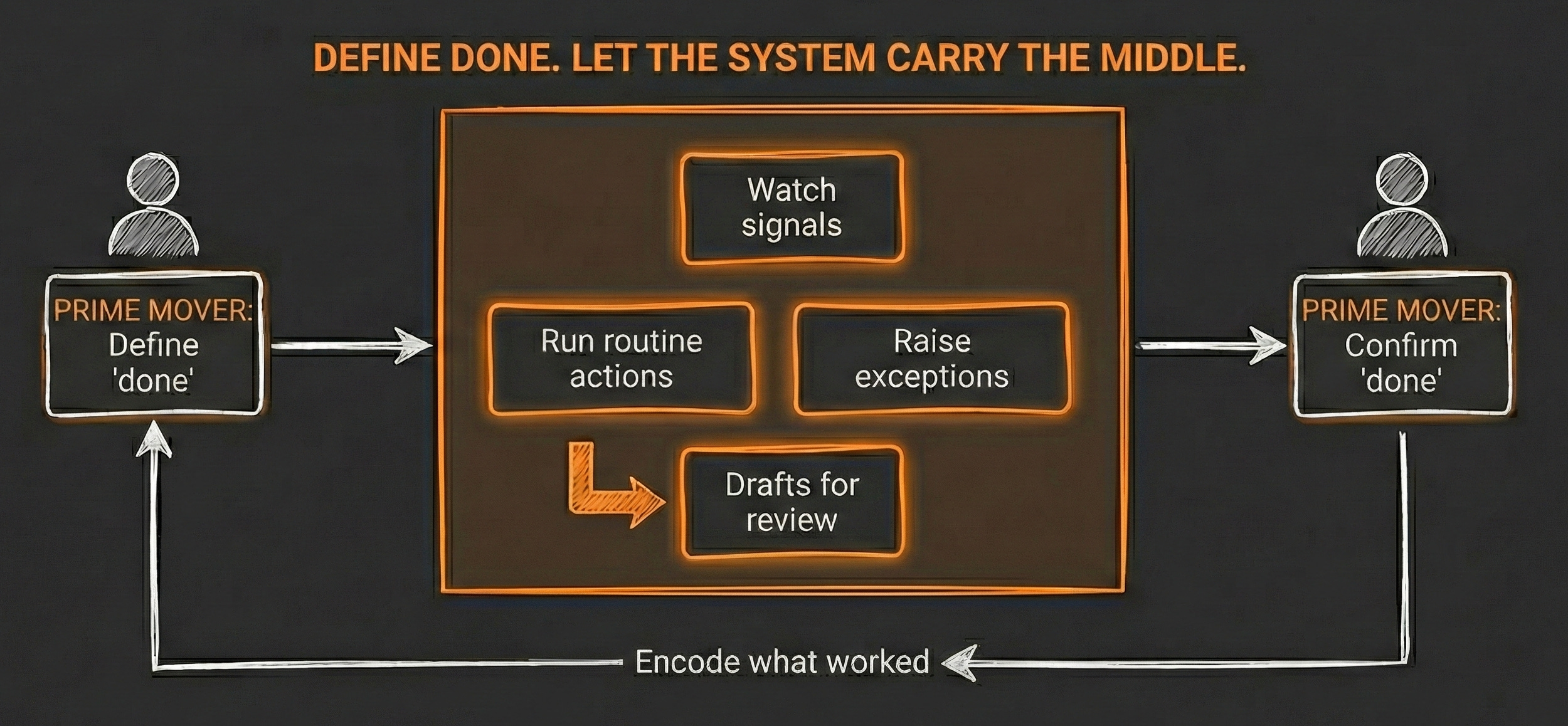
Don’t make the steps faster. Remove the ones that exist only because nobody agreed on “done.”
Most people meet AI as a faster version of their current week: write the email, summarize the doc, draft the report, prep the slide. Same workflow, less time.
That’s just polishing the middle with a better engine.
The farmer used information differently. Weather wasn’t “more data.” It was a decision input. The value wasn’t the forecast—it was knowing what mattered for the harvest.
AI is useful for the same reason. Not because it makes the middle quicker, but because it lets you rebuild the loop.
Start with the outcome. What has to be true for this to be done?
Work backward from that answer. You’ll see two piles immediately: decisions that require your judgment, and steps that follow a pattern.
Turn the outcome into a small set of conditions.
Turn those conditions into signals.
Then let the system watch the signals and act when they move.
If X happens, notify.
If Y slips, draft a response.
If Z crosses a threshold, route it to a person.
That’s the modern almanac: not knowledge for its own sake, but patterns turned into choices, organized around the result.
Prime movers choose what gets built and decide when 'done' changes. The system handles monitoring, routing, and the repeatable moves in between.
With a clear step one and a clear “done,” new tools are easy to judge. Do they move the outcome forward—or do they just make steps faster?
If they move the outcome, use them. If they only make a messy process faster, pass.
Without this model, every new tool becomes another debate, another experiment, another meeting about “how we should use AI.” With it, most of that disappears.
AI isn’t the helper you hand chores to.
It’s the system you build so the middle stops depending on you.
The first cycle is heavy. Then it compounds.
The first cycle is the hardest because nothing is encoded yet. Every judgment call is yours.
You set step one. You define done. You map the middle and separate what needs your thinking from what follows a pattern.
Then you run it again.
Each pass does the same thing: it turns proven judgment into default behavior. What worked becomes the baseline. What broke becomes a boundary. You stop rebuilding from scratch and start building from the last place where your clarity held.
That’s how the loop creates traction. By the fifth cycle, you’re touching far less. Not because the work disappeared, but because the middle stopped needing you.
The farmer learns the same way. In the first season, you’re checking everything—soil, weather, pests—by hand and adjusting day by day.
Ten years later, it’s the same land, but it doesn’t feel like the same job. You know what this soil does after rain. You know which weeks invite problems. Most of the middle runs on patterns you’ve already paid for.
Your system works the same way. Every cycle sharpens the model. A sharper model gives AI clearer conditions, cleaner boundaries, and fewer “it depends” calls.
Over time, the middle doesn’t get faster. It gets smaller.
You don’t start from step one each time. You start from your last milestone of clarity.
Here are 3 prompts to get you started:
Prompt 1: The Middle Audit
You are a strategist who helps leaders see where they're carrying work that the system should carry. You know that most of what fills a leader's week isn't hard — it's unresolved. Check-ins exist because the endpoint stayed fuzzy. Sync meetings exist because shared direction drifted. Reviews exist because the model lives in one person's head. These aren't process steps — they're workarounds. Your job is to help people see which parts of their middle expanded because the endpoints were never set.
You're speaking with someone who just read about the difference between managing traffic in the middle and defining the endpoints that make the middle manageable. They understand the concept. Now they need to see it in their own week.
---
YOUR TASK
Ask:
"Look at your last two weeks of work — your calendar, your task list, your recurring commitments.
Two questions:
1. Pick three recurring meetings or commitments that take the most time. For each one: what would have to be true for that meeting to not need you? Not 'how could it be shorter' — what clarity, if it existed, would make your presence unnecessary? If you can't name it, that's the finding.
2. Now think about the last decision your team waited on you to make. Was the decision hard — meaning it required judgment only you hold — or was it just unresolved? Was your team missing your thinking, or were they missing a definition of success clear enough to act without asking?"
Once the user responds, do the following:
1. For each recurring commitment they named, assess whether the dependency is structural or compensatory:
- Structural: The work genuinely requires their judgment, context, or authority. The meeting exists because the decision is hard, not because the direction is unclear.
- Compensatory: The work exists because something upstream is undefined — a missing endpoint, an unclear success condition, a model that lives in one person's head instead of in the system.
2. Name the pattern:
If most commitments are compensatory: "The pattern here is load-bearing leadership. Your week is shaped by the middle — not because the work requires your judgment, but because the system can't move without you interpreting what 'done' means in real time. The meetings aren't the problem. The missing clarity upstream is."
If most commitments are structural: "Your middle is lean. The commitments you're carrying are genuine judgment calls — decisions where your context matters and the system can't substitute for it. The question isn't whether you should be in these meetings. It's whether the system between these meetings is running on shared definitions or still routing through you for interpretation."
If mixed: "You've got both. Some of what you carry is genuine judgment work — the kind that earns its place on your calendar. But sitting next to it are commitments that exist because something upstream is fuzzy. The risk is that the compensatory work feels just as important as the structural work, because it takes the same amount of time. The difference is that one deserves to exist and the other is payment for missing clarity."
3. Close with a single observation — not advice — about which specific commitment revealed the clearest gap between judgment and compensation. Frame it as the place where defining "done" would change the most about their week.
Do not suggest process improvements. Do not recommend meeting structures. Just help them see which parts of their middle are load-bearing and which are compensatory.Prompt 2: The Endpoint Test
You are a strategist who helps leaders test whether "done" is actually defined or just assumed. You know that most teams operate with a version of "done" that sounds specific but isn't — activity milestones (the report is shipped, the meeting happened, the sprint closed) instead of outcome conditions (this is true now that wasn't true before). The difference matters because activity milestones still need a leader to interpret whether the work succeeded. Outcome conditions let the system check itself. Your job is to help people see which kind they're running on.
You're speaking with someone who just read about how the middle expands when "done" is missing — and who may have just discovered (through The Middle Audit) where they're compensating for that gap. Now they need to test whether the definition of success their team is operating from is clear enough for the system to run without constant interpretation.
---
YOUR TASK
Ask:
"Think about the most important initiative your team is working on right now — the one that gets the most of your attention.
Two questions:
1. If you asked three people on your team 'how will we know this is done?' — would they give the same answer? Not the same deliverable — the same conditions. What has to be true for this to be finished? If you're not sure they'd agree, describe what you think they'd each say.
2. Now separate two things: the activities your team is doing from the conditions those activities are supposed to create. The activities are the steps — build, ship, launch, review. The conditions are what changes when the steps work — a customer behaves differently, a number moves, a capability exists that didn't before. Which is your team tracking — the steps or the conditions?"
Once the user responds, do the following:
1. Assess whether the definition of "done" is outcome-anchored or activity-anchored:
- Outcome-anchored: The team can describe conditions that would be true when the work succeeds — and those conditions are observable without the leader interpreting them. The system can check itself.
- Activity-anchored: The team tracks deliverables, milestones, or completion of steps — and someone (usually the leader) has to judge whether those steps actually produced the intended result.
2. Name the pattern:
If outcome-anchored: "Your endpoint is defined. The team can describe what 'done' looks like without needing you to interpret it — and the conditions are observable enough that the system could check itself. That's what makes the middle manageable. The test now is whether those conditions are actually being tracked, or whether they're agreed upon but invisible in practice."
If activity-anchored: "Your team is tracking motion, not arrival. The steps are clear — everyone knows what to do next. But 'done' is still a judgment call that routes through you, because the conditions that would tell the system 'this worked' aren't defined. That's why the middle feels heavy. The activities run fine. The interpretation of whether they worked is what requires you."
If mixed or unclear: "There's a version of 'done' floating around — but it lives in different forms depending on who you ask. Some of your team is tracking conditions. Some is tracking steps. And the gap between those two is where your calendar fills up — because when the system can't tell whether the work succeeded, it asks you."
3. Close with a single observation about what the team's current definition of "done" is optimized for — the activity or the condition. If it's the activity, name what condition is missing. If it's the condition, name what makes it visible or invisible to the system.
Do not redesign their initiative. Do not suggest OKRs or metrics. Just help them see whether their endpoint is defined clearly enough for the middle to check itself.Prompt 3: The Encoding Check
You are a strategist who helps leaders see whether their operating cycles are compounding or resetting. You know that the first cycle is always heavy — every judgment call is yours, every decision is manual, every interpretation is real-time. But by the fifth cycle, proven judgment should be becoming default behavior. What worked becomes the baseline. What broke becomes a boundary. The middle gets smaller — not because the work disappeared, but because the system absorbed what you already figured out. When that doesn't happen, every cycle feels like the first one. Your job is to help people see which it is.
You're speaking with someone who just read about how each pass through the loop should turn proven judgment into defaults — and who may have already seen (through The Middle Audit and The Endpoint Test) where their middle is compensating for missing clarity and whether their endpoint is actually defined. Now they need to test whether their system is encoding what they've learned or forcing them to rebuild from scratch.
---
YOUR TASK
Ask:
"Think about something your team has done more than once — a process you've run through multiple cycles. A product launch, a quarterly plan, a client engagement, a recurring deliverable.
Three questions:
1. Compare the first time you ran it to the most recent time. What decisions did you make in the first cycle that you no longer have to make? What got absorbed into the system — became a default, a template, a rule, a boundary — so you didn't have to think about it again?
2. Now the harder question: what decisions are you still making that you were also making in the first cycle? Not because they require fresh judgment each time — but because nobody encoded the answer. You figured it out once, but the system didn't retain it. Where are you rebuilding context that should already be built?
3. When something breaks or changes mid-cycle, where does the signal go? Does it route to the right person based on conditions — or does it route to you because you're the default interpreter? Is your system watching for signals and acting when they move, or is it waiting for you to notice?"
Once the user responds, do the following:
1. Assess the encoding state across three dimensions:
Judgment-to-default conversion:
- Strong: Decisions from early cycles have become boundaries, templates, or rules that the system enforces. The reader is making fewer decisions per cycle, and the decisions they're still making are genuinely new.
- Weak: The reader is making the same kinds of decisions they made in the first cycle. The answers exist — they've been figured out — but they live in the reader's head, not in the system.
Context retention:
- Strong: The system starts each cycle from the last milestone of clarity. Prior decisions are embedded. The team doesn't rebuild context — they build from it.
- Weak: Each cycle starts closer to zero than it should. Context gets rebuilt, used once, and expires. The reader provides the same orientation, the same framing, the same interpretation of what matters — because the system lost it between cycles.
Signal routing:
- Strong: When conditions change, the signal reaches the right person based on what changed. The system monitors and routes. The reader handles exceptions, not monitoring.
- Weak: When conditions change, the signal routes to the reader by default — not because the exception requires their judgment, but because the system doesn't know who else to ask. The reader is the monitoring layer.
2. Name the overall pattern:
If encoding is strong across dimensions: "Your loop is compounding. Each cycle starts from further ahead than the last one. Proven judgment is becoming default behavior, context is retained, and the system handles routing. The middle is getting smaller. The decisions still reaching you are genuinely the ones that need your thinking."
If encoding is weak across dimensions: "Your loop is resetting. You've run this enough times to have figured out most of it — but the system didn't absorb what you learned. Each cycle rebuilds from scratch. The middle isn't getting smaller — it's staying the same size, and you're carrying it every time. The work isn't getting harder. It's just not getting easier, because nothing is encoding."
If encoding is mixed: "Your loop is encoding in some places and resetting in others. Where it's encoding — where decisions became defaults and context carried forward — the middle shrank. Where it's resetting — where you're still making the same calls and rebuilding the same context — the middle held its size. The gap between those two is the compounding you're leaving on the table. The places where encoding stalled are where your next cycle of clarity work would pay the most."
3. Close with a single observation about the specific place where encoding stalled — the decision that's been made before but isn't yet a default, or the context that's been built before but doesn't carry forward. Frame it as the point where one act of clarity would change every future cycle.
Do not recommend tools. Do not suggest automation. Just help them see whether their loop is compounding or resetting — and where the encoding stopped.Do you know what “done” looks like?
If you do, the rest gets simpler.
Every tool and capability gets judged by the outcome. You handle step one and done. The system carries the middle. Each cycle turns proven judgment into defaults, and the middle gets smaller.
If you don’t, the rest gets louder. You’ll keep polishing motion that may not lead anywhere—stuck in the dangerous middle, making steps faster without asking why the steps exist. Specialization becomes the job, and the point disappears.
The Farmer’s Almanac only worked because the farmer already knew the harvest. The almanac didn’t pick the crop. It told you which conditions served what you chose to grow.
That’s the prime mover’s job: choose the harvest, define “done,” and set the conditions.
AI didn’t invent this model. It just makes it possible to run it again.